The emergence of coronavirus disease 2019 (COVID-19) as a global pandemic presents a serious health threat to many low-and-middle-income countries (LMICs) and the livelihoods of its people. The need for accurate, real-time data is urgent, so that health policy and planning can be updated to combat the threat. Obtaining those data requires innovation in data collection and aggregation, especially under lockdown restrictions.
Artificial Intelligence (AI) and Data Science (DS) innovations are needed to get accurate, real-time data, using multiple data sources. In many LMICs, there are methodological gaps in data integration and a lack of information and research capacity to make informed decisions and guide public health policy. The absence of data makes it difficult to identify vulnerable populations and to give them appropriate information for their health.
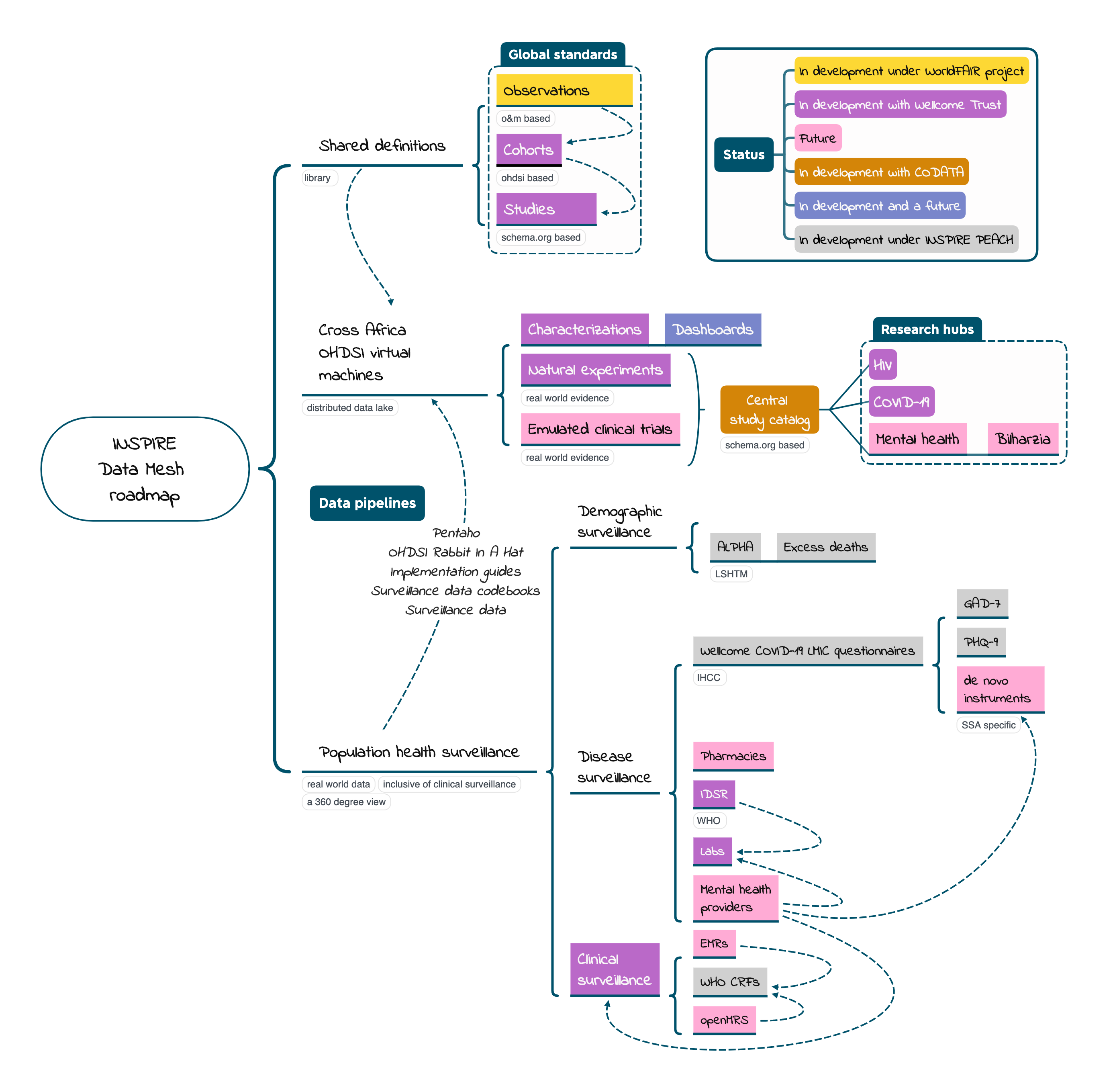
This project proposes to develop the key elements of a coordinated Pan-African COVID-19 data ecosystem. We will build a robust suite of data standards and technologies, diverse data integration methodologies, using the power of AI and DS for analysis and oversight through a trusted governance and policy environment.
The emergence of big data, and related to that, of machine learning technologies have brought new challenges and opportunities to those working with health data. This involves a re-defining of training approaches to include skills needed to analyse data from multiple sources to avoid bias and oversight. While the traditional manual ways of collecting health data through surveys, HDSS tools still remain core, challenges in organising, utilising and sharing data have raised the prospects of how to utilise AI to turbocharge data discovery, data collection and analysis processes. The overarching question being what insights can machine learning and AI bring to health researchers and professionals. And how can existing processes be adjusted to facilitate AI technologies. With these aspects in mind, INSPIRE PEACH has setup a training program that can help uncover and address the skills and knowledge gaps of health data professionals with several pathways of training in mind such as data trackers, data managers, analysts. The courses were developed with the aim to support scientists working on health data mapping and transformation tasks and data discovery, access and reuse.
Online news and data such as that published on social networks have been extremely popular for social research, being considered one of the “largest, richest and most dynamic evidence base of human behavior, bringing new opportunities to understand individuals, groups and society”.
Infodemiology / Infoveillance can be defined as the science of distribution and determinants of information in an electronic medium, specifically the Internet, or in a population, with the ultimate aim to inform public health and public policy. Infodemiology data can be collected and analyzed in near real time.
Examples for infodemiology applications include: the analysis of queries from Internet search engines to predict disease outbreaks (eg. influenza); monitoring peoples' status updates on microblogs such as Twitter for syndromic surveillance; detecting and quantifying disparities in health information availability; identifying and monitoring of public health relevant publications on the Internet (eg. anti-vaccination sites, but also news articles or expert-curated outbreak reports); automated tools to measure information diffusion and knowledge translation, and tracking the effectiveness of health marketing campaigns.
The PEACH project developed an aggregator of news and academic articles focussing on covid-19 in Malawi and Kenya.